はじめに
KPOPに興味がある人なら誰しも一度は見たことがあるであろう、MR除去(MR Removed)の動画。ただ、自分の見たいパフォーマンスビデオの動画に限っては、MR除去された動画がYouTubeに無かったりしますよね。そのため、今回はMR除去の技術を解説するとともに、皆さんが実際にMR除去をできるようになるソースコードを紹介します。
MR除去とは?
まずはMR除去を簡単に説明します。KPOPのパフォーマンス動画では、アーティストは歌いながら踊って、とても大変そうですよね。しかし、激しい踊りなのにも関わらず、歌声はしっかりしています。それは、被せに助けられているからなのです。被せとは、パフォーマンスでのマイク入力(生歌)とは別にCDの音源を上から被せて、歌声を安定させることを指します。その被せをMR除去の技術を用いて取り去り、完全な生歌だけを聞こうという考えなのです。
MR除去技術の概要
MR除去では、昔からある音声差分を抽出する技術を活用しています。たとえば、ボーカル+伴奏の音声ファイルに対して、伴奏のみの音声ファイルをぶつけると、その差分として、ボーカルが抽出されます。これによりMR除去では、生歌(被せあり)の音声に対して、CD音源をぶつけると、生歌だけが抽出できるのです。
ボーカルリムーバー(AI)との違い
AIによるボーカル抽出では、音声差分ではなくボーカル、伴奏として切り分けるだけになります。そのためパフォーマンスの音声をAIに抽出させようとすると、被せが残った状態の生歌が抽出されるのです。
実際にやってみよう!
実際にやってみようということで、今回はパソコンを持っていない方でも簡単に実行できるように、google colabを使用します。
ステップ1
Google Colabにアクセスし、ノートブックを新規作成します。
ステップ2
セルを新規作成します。
そして、以下のコード1を貼り付けます。
!pip install librosa soundfile scipy yt-dlp gradio貼り付ける際に、iPhoneユーザーだと長押ししても青カーソルが出ない場合があるため、三本指で長押しし、この画面を表示させ、ペーストします。
ステップ3
もう一度セルを作成し、以下のコード2をペーストします。
import os
import librosa
import soundfile as sf
import numpy as np
import scipy.signal as sps
import yt_dlp
import gradio as gr
# ----- 音声処理関数 -----
def align_audio(original_file, karaoke_file):
y1, sr1 = librosa.load(original_file, sr=None, mono=True)
y2, sr2 = librosa.load(karaoke_file, sr=None, mono=True)
if sr1 != sr2:
raise ValueError("サンプリングレートが異なります。")
y1 = y1 / np.max(np.abs(y1))
y2 = y2 / np.max(np.abs(y2))
corr = sps.correlate(y1, y2, mode='full')
lags = sps.correlation_lags(len(y1), len(y2), mode='full')
best_lag = lags[np.argmax(corr)]
if best_lag > 0:
y1_aligned = y1[best_lag:]
y2_aligned = y2
else:
y1_aligned = y1
y2_aligned = y2[abs(best_lag):]
min_len = min(len(y1_aligned), len(y2_aligned))
return y1_aligned[:min_len], y2_aligned[:min_len], sr1
def extract_vocals(y1, y2, sr, scale_factor=1.0):
n_fft = 2048
hop_length = 512
orig_stft = librosa.stft(y1, n_fft=n_fft, hop_length=hop_length)
kara_stft = librosa.stft(y2, n_fft=n_fft, hop_length=hop_length)
orig_mag, orig_phase = np.abs(orig_stft), np.angle(orig_stft)
kara_mag, _ = np.abs(kara_stft), np.angle(kara_stft)
vocal_mag = np.maximum(orig_mag - kara_mag * scale_factor, 0)
vocal_stft = vocal_mag * np.exp(1j * orig_phase)
vocal_wave = librosa.istft(vocal_stft, hop_length=hop_length)
return vocal_wave / np.max(np.abs(vocal_wave))
# ----- YouTube ダウンロード関数 -----
def download_audio_from_youtube(url, output_dir):
ydl_opts = {
'format': 'bestaudio/best',
'outtmpl': os.path.join(output_dir, '%(id)s.%(ext)s'),
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
'preferredquality': '192',
}],
'quiet': True,
'no_warnings': True,
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info_dict = ydl.extract_info(url, download=True)
filename = ydl.prepare_filename(info_dict)
base, _ = os.path.splitext(filename)
audio_file = base + ".wav"
return audio_file
# ----- メイン処理関数 (Gradio用) -----
def process_vocals(music1_url, music2_url, scale_factor, output_filename):
# ダウンロード先は "Audios" フォルダ(存在しない場合は作成)
download_dir = os.path.join(os.getcwd(), "Audios")
if not os.path.exists(download_dir):
os.makedirs(download_dir)
# ダウンロード実行
file1 = download_audio_from_youtube(music1_url, download_dir)
file2 = download_audio_from_youtube(music2_url, download_dir)
# タイミング補正
y1, y2, sr = align_audio(file1, file2)
# ボーカル抽出
vocals = extract_vocals(y1, y2, sr, scale_factor)
# 完成音源の出力先は "extracted" フォルダ
output_dir = os.path.join(os.getcwd(), "extracted")
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 出力ファイル名(拡張子 .wav を付加)
if not output_filename:
output_filename = "extracted_vocals"
output_file = os.path.join(output_dir, output_filename + ".wav")
sf.write(output_file, vocals, sr)
return output_file
# ----- Gradio インターフェイスの定義 -----
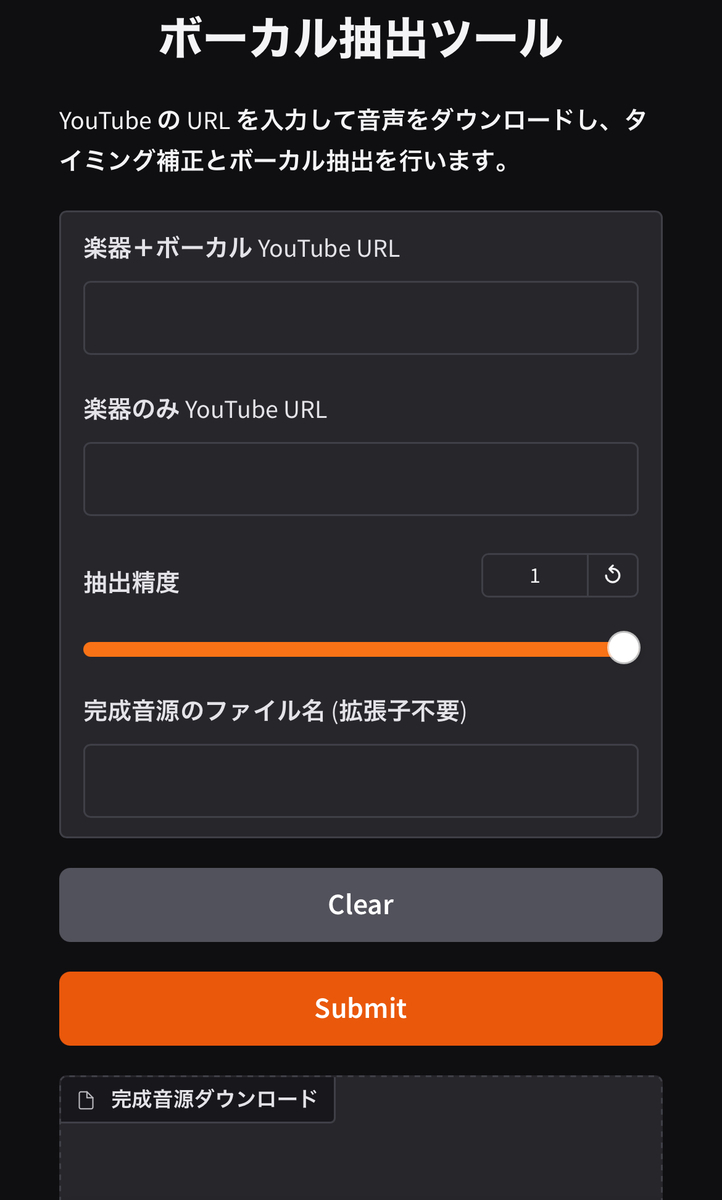
iface = gr.Interface(
fn=process_vocals,
inputs=[
gr.Textbox(label="楽器+ボーカル YouTube URL"),
gr.Textbox(label="楽器のみ YouTube URL"),
gr.Slider(0.0, 1.0, step=0.01, value=1.0, label="抽出精度"),
gr.Textbox(label="完成音源のファイル名 (拡張子不要)")
],
outputs=gr.File(label="完成音源ダウンロード"),
title="ボーカル抽出ツール",
description="YouTube の URL を入力して音声をダウンロードし、タイミング補正とボーカル抽出を行います。"
)
iface.launch()
ペーストを終えたらこんな感じ。
ステップ4
コードの実行をします。コードの左側の▶️をふたつのコードともに実行します。実行が完了すると、Gradioが起動し、URLが表示されますので、アクセスします。
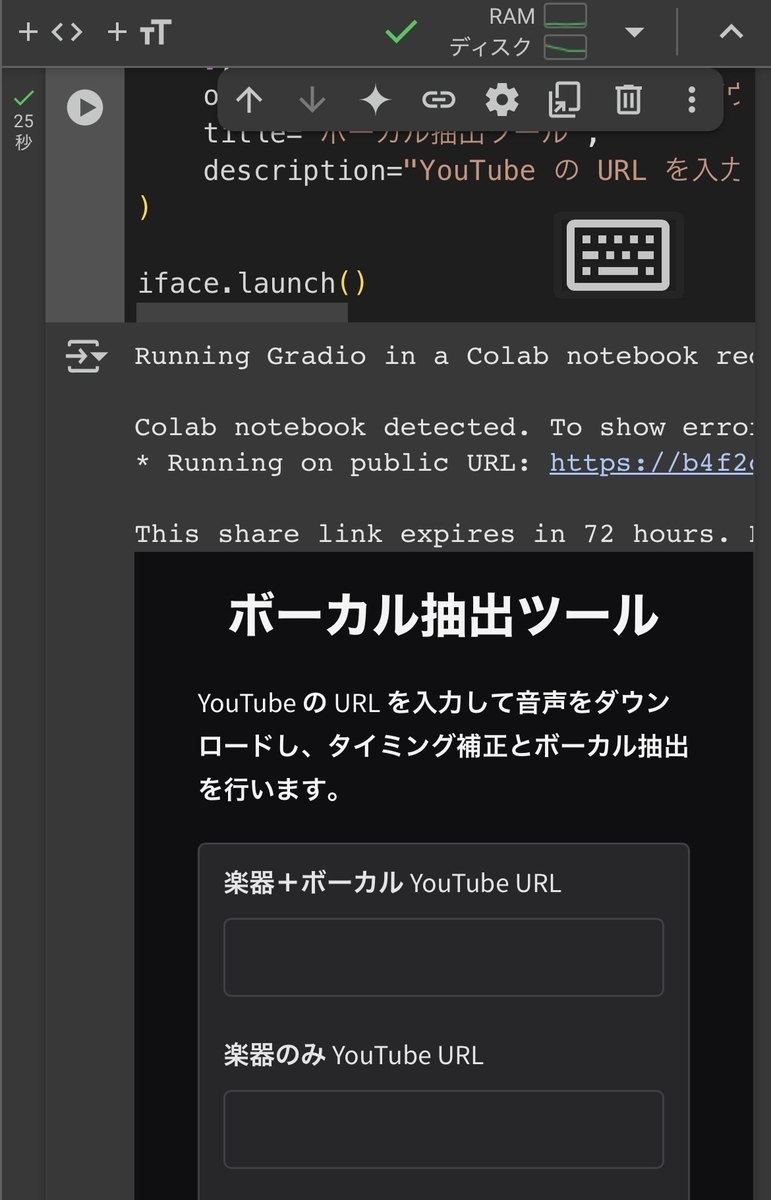
ステップ5
後は自分の好きなパフォーマンスビデオのYouTubeURLを楽器+ボーカルの入力欄に、MV等のCD音源のURLを楽器の入力欄に記述します。そして、抽出精度は基本的に0.3程度がオススメです。
まとめ
今回はMR除去の技術とそのソースコードを紹介しました。これで自分の好きなパフォーマンスビデオの生歌音源を聞くことができます。何か不明な点や不具合などありましたら、コメント欄にてお待ちしております。